{ok, MasterHostname} = ts_utils:node_to_hostname(node()),
case {ts_utils:is_ip(MasterHostname), ts_utils:is_ip(Host), ts_utils:is_ip(HostIP)} of
%% must be hostname and not ip:
{false, true, _} ->
io:format(standard_error,"ERROR: client config: 'host' attribute must be a hostname, "++ "not an IP ! (was ~p)~n",[Host]),
exit({error, badhostname});
{true, true, _} ->
%% add a new client for each CPU
lists:duplicate(CPU,#client{host = Host,
weight = Weight/CPU,
maxusers = MaxUsers});
{true, _, true} ->
%% add a new client for each CPU
lists:duplicate(CPU,#client{host = HostIP,
weight = Weight/CPU,
maxusers = MaxUsers});
{_, _, _} ->
%% add a new client for each CPU
lists:duplicate(CPU,#client{host = Host,
weight = Weight/CPU,
maxusers = MaxUsers})
end
tarting Tsung
Log directory is: /root/.tsung/log/20160621-1334
[os_mon] memory supervisor port (memsup): Erlang has closed
[os_mon] cpu supervisor port (cpu_sup): Erlang has closed
其中, 其日志为:/root/.tsung/log/20160621-1334。
4. 查看压测报告
进入其生成压测日志目录,然后生成报表,查看压测结果哈:
cd /root/.tsung/log/20160621-1334
/usr/local/lib/tsung/bin/tsung_stats.pl
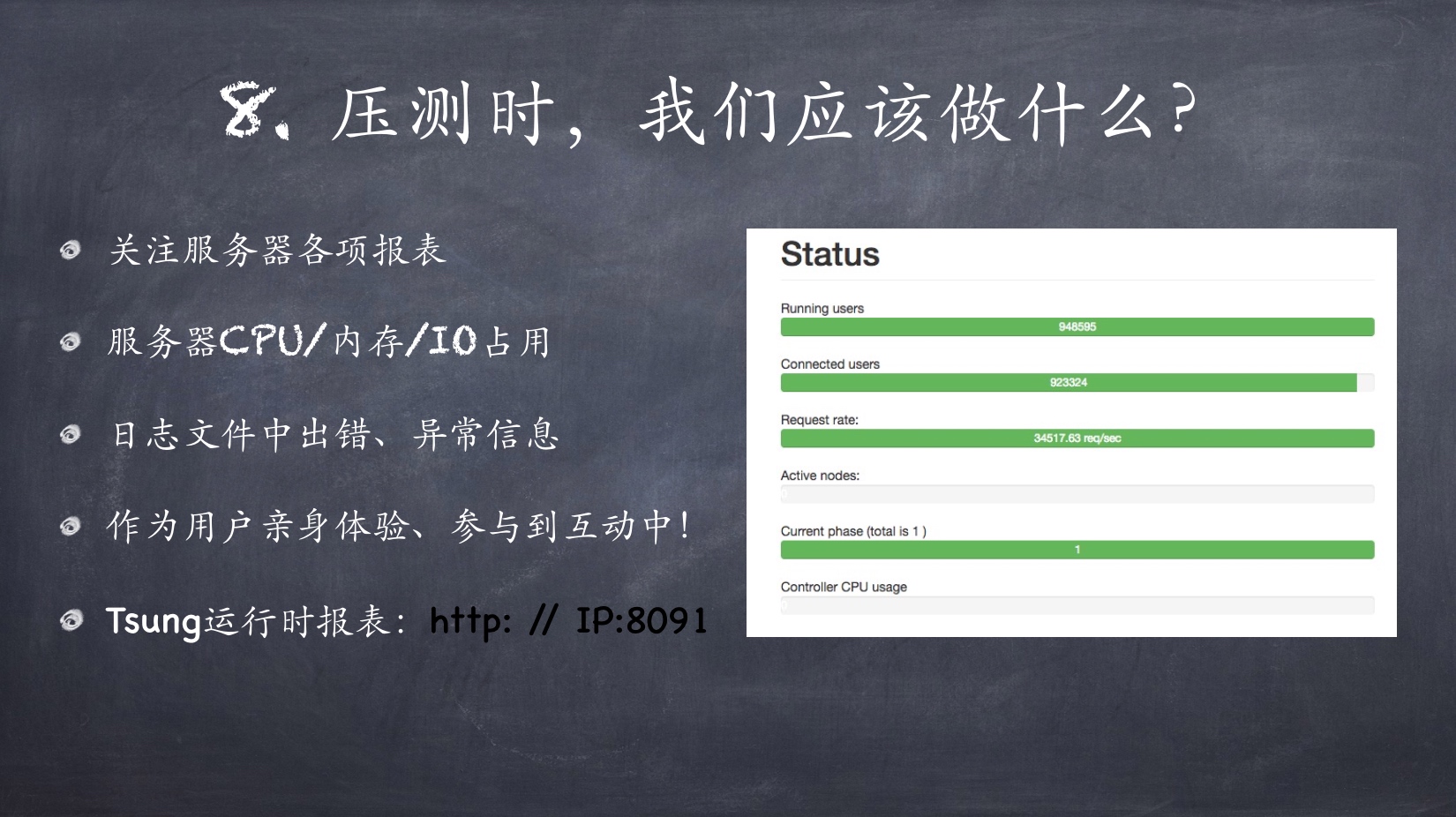
echo "open your browser (URL: http://IP:8000/report.html) and vist the report now :))"
/usr/bin/python -m SimpleHTTPServer
app:use(function(req, res, next)
local token = ngx.req.get_headers()["Authorization"]
-- 校验失败,err为错误代码,比如 400
local payload, err = verify_jwt(token)
if err then
res:status(err):send("bad access token reqeust")
return
end
-- 注入进当前上下文中,避免每次从token中获取
req.params.uid = payload.uid
next()
end)
针对具体路径进行设定权限拦截,较粗粒度;比如 /user 只允许已登陆授权用户访问
app:use("/user", function(req, res, next)
if not req.params.uid then
-- 注意,这里没有调用next()方法,请求到这里就截止了,不在匹配后面的路由
res:status(403):send("not allowed reqeust")
else
next() -- 满足以上条件,那么继续匹配下一个路由
end
end)
local function check_token(req, res, next)
if not req.params.uid then
res:status(403):send("not allowed reqeust")
else
next()
end
end
local function check_master(req, res, next)
if not req.params.uid ~= master_uid then
res:status(403):send("not allowed reqeust")
else
next()
end
end
local lor = require("lor.index")
local app = lor()
-- 声明一个group router
local user_router = lor:Router()
-- 假设查看是不需要用户权限的
user_router:get("/feedback", function(req, res, next)
end)
user_router:put("/feedback", check_token, function(req, res, next)
end)
user_router:post("/feedback", check_token, function(req, res, next)
end)
-- 只有管理员才有权限删除
user_router:delete("/feedback", check_master, function(req, res, next)
end)
-- 以middleware的形式将该group router加载进来
app:use("/user", user_router())
......
app:run()
-- todo: support upstream id
api_ctx.matched_upstream = (route.dns_value and
route.dns_value.upstream)
or route.value.upstream
直接替换为下面代码即可解决燃眉之急:
local up_id = route.value.upstream_id
if up_id then
local upstreams = core.config.fetch_created_obj("/upstreams")
if upstreams then
local upstream = upstreams:get(tostring(up_id))
if not upstream then
core.log.error("failed to find upstream by id: " .. up_id)
return core.response.exit(502)
end
if upstream.has_domain then
local err
upstream, err = lru_resolved_domain(upstream,
upstream.modifiedIndex,
parse_domain_in_up,
upstream)
if err then
core.log.error("failed to get resolved upstream: ", err)
return core.response.exit(500)
end
end
if upstream.value.pass_host then
api_ctx.pass_host = upstream.value.pass_host
api_ctx.upstream_host = upstream.value.upstream_host
end
core.log.info("parsed upstream: ", core.json.delay_encode(upstream))
api_ctx.matched_upstream = upstream.dns_value or upstream.value
end
else
api_ctx.matched_upstream = (route.dns_value and
route.dns_value.upstream)
or route.value.upstream
end
2021/02/23 02:32:20 [error] 7#7: init_worker_by_lua error: /usr/local/share/lua/5.1/resty/worker/events.lua:175: attempt to index local 'handler_list' (a nil value)
stack traceback:
/usr/local/share/lua/5.1/resty/worker/events.lua:175: in function 'do_handlerlist'
/usr/local/share/lua/5.1/resty/worker/events.lua:215: in function 'do_event_json'
/usr/local/share/lua/5.1/resty/worker/events.lua:361: in function 'post'
/usr/local/share/lua/5.1/resty/worker/events.lua:614: in function 'configure'
/usr/local/apisix/apisix/init.lua:94: in function 'http_init_worker'
init_worker_by_lua:5: in main chunk
推荐做法是延迟加载,在该模块被加载时进行引用。
local events
local events_list
......
function _M.init_worker()
......
events = require("resty.worker.events")
events_list = events.event_list(
"discovery_consul_update_application",
"updating"
)
if 0 ~= ngx.worker.id() then
events.register(discovery_consul_callback, events_list._source, events_list.updating)
return
end
......
end
单元测试依赖
单元测试代码的执行,会在你提交PR代码后自动执行持续集成行为内执行。
首先,需要本机执行单元测试前,需要提前准备好所需Docker测试实例:
docker run --rm --name consul_1 -d -p 8500:8500 consul:1.7 consul agent -server -bootstrap-expect=1 -client 0.0.0.0 -log-level info -data-dir=/consul/data
docker run --rm --name consul_2 -d -p 8600:8500 consul:1.7 consul agent -server -bootstrap-expect=1 -client 0.0.0.0 -log-level info -data-dir=/consul/data
docker run --rm -d \
-e ETCD_ENABLE_V2=true \
-e ALLOW_NONE_AUTHENTICATION=yes \
-e ETCD_ADVERTISE_CLIENT_URLS=http://0.0.0.0:2379 \
-e ETCD_LISTEN_CLIENT_URLS=http://0.0.0.0:2379 \
-p 2379:2379 \
registry.api.weibo.com/wesync/wbgw/etcd:3.4.9
```yaml
discovery:
consul_kv:
servers:
- "http://127.0.0.1:8500"
- "http://127.0.0.1:8600"
prefix: "upstreams"
skip_keys: # if you need to skip special keys
- "upstreams/unused_api/"
timeout:
connect: 1000 # default 2000 ms
read: 1000 # default 2000 ms
wait: 60 # default 60 sec
weight: 1 # default 1
fetch_interval: 5 # default 3 sec, only take effect for keepalive: false way
keepalive: true # default true, use the long pull way to query consul servers
default_server: # you can define default server when missing hit
host: "127.0.0.1"
port: 20999
metadata:
fail_timeout: 1 # default 1 ms
weight: 1 # default 1
max_fails: 1 # default 1
```
......
The `keepalive` has two optional values:
- `true`, default and recommend value, use the long pull way to query consul servers
- `false`, not recommend, it would use the short pull way to query consul servers, then you can set the `fetch_interval` for fetch interval
### What this PR does / why we need it:
<!--- Why is this change required? What problem does it solve? -->
<!--- If it fixes an open issue, please link to the issue here. -->
### Pre-submission checklist:
* [ ] Did you explain what problem does this PR solve? Or what new features have been added?
* [ ] Have you added corresponding test cases?
* [ ] Have you modified the corresponding document?
* [ ] Is this PR backward compatible? **If it is not backward compatible, please discuss on the [mailing list](https://github.com/apache/apisix/tree/master#community) first**
按照模板格式填写,省心省力,如下:
### What this PR does / why we need it:
As I mentioned previously in the mail-list, my team submit our `consul_kv` discovery module now.
More introductions here:
https://github.com/yongboy/apisix/blob/consul_kv/doc/discovery/consul_kv.md
### Pre-submission checklist:
* [x] Did you explain what problem does this PR solve? Or what new features have been added?
* [x] Have you added corresponding test cases?
* [x] Have you modified the corresponding document?
* [x] Is this PR backward compatible? **If it is not backward compatible, please discuss on the [mailing list](https://github.com/apache/apisix/tree/master#community) first**
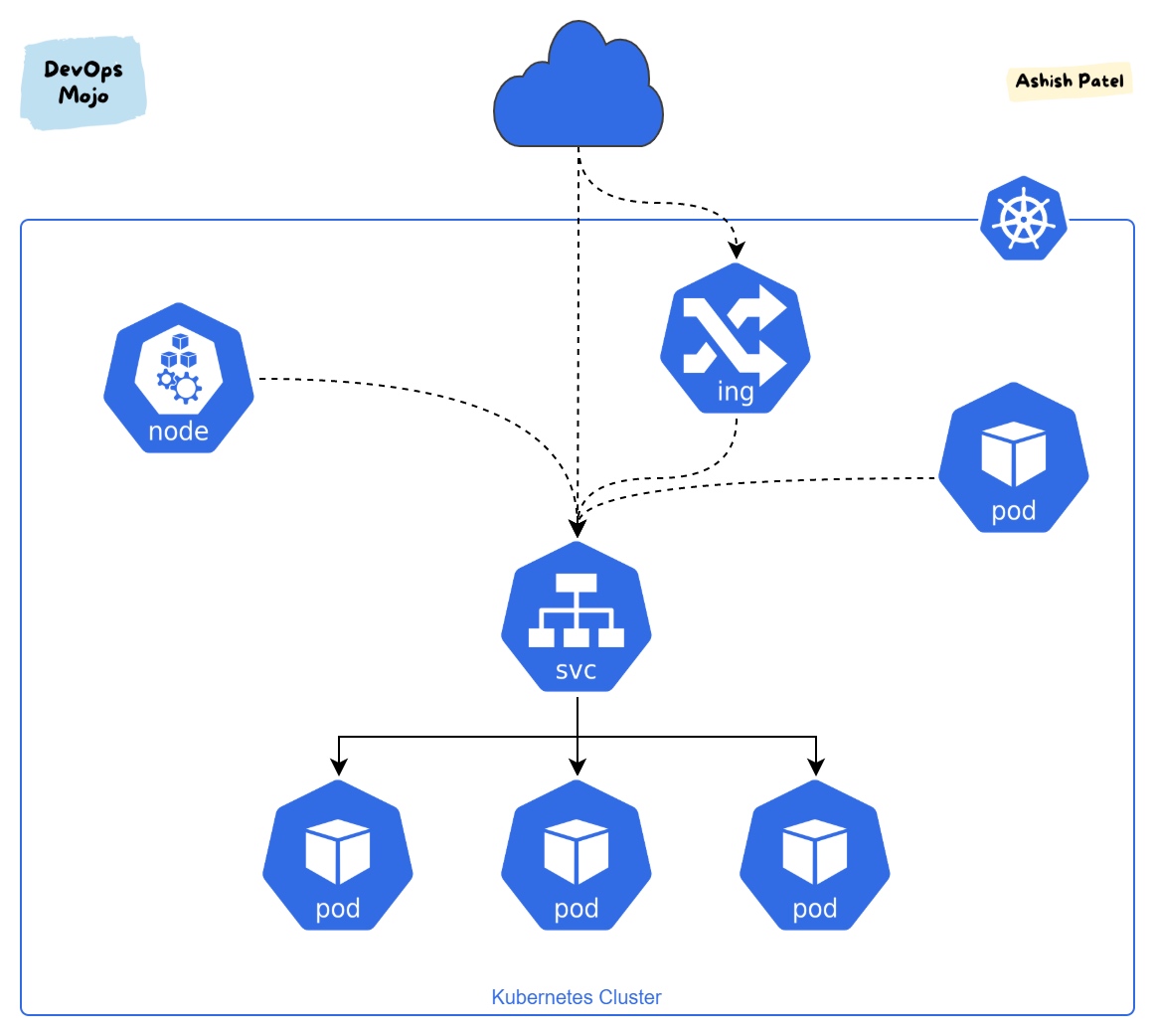
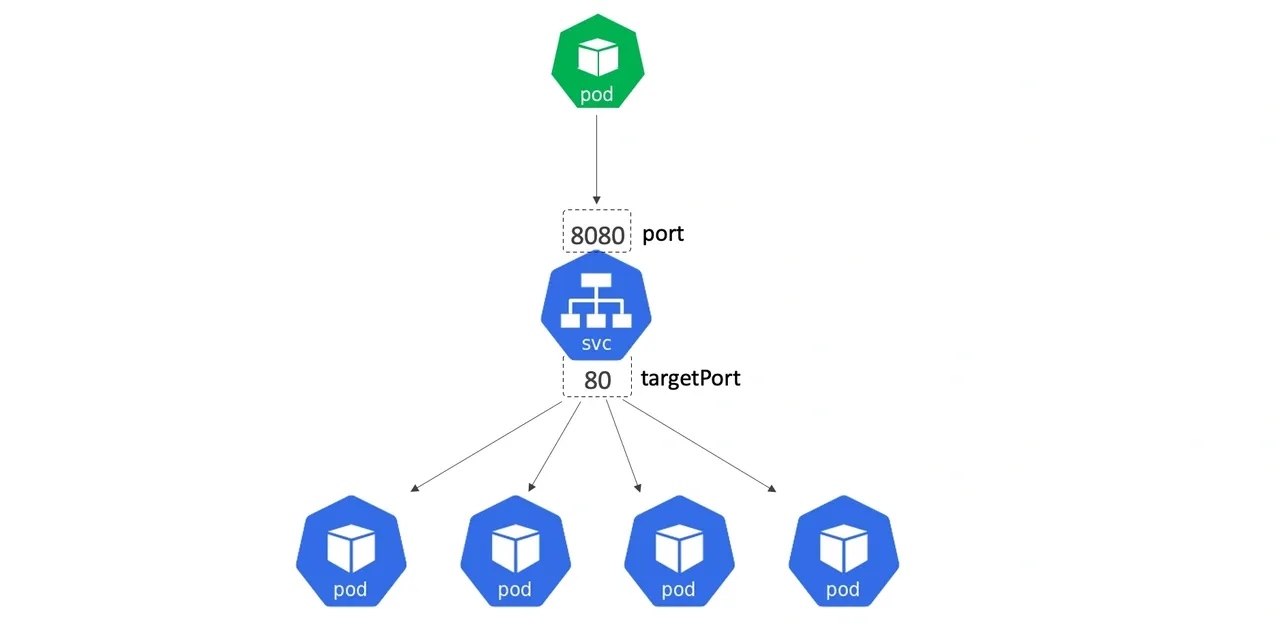
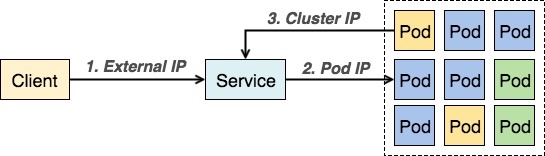
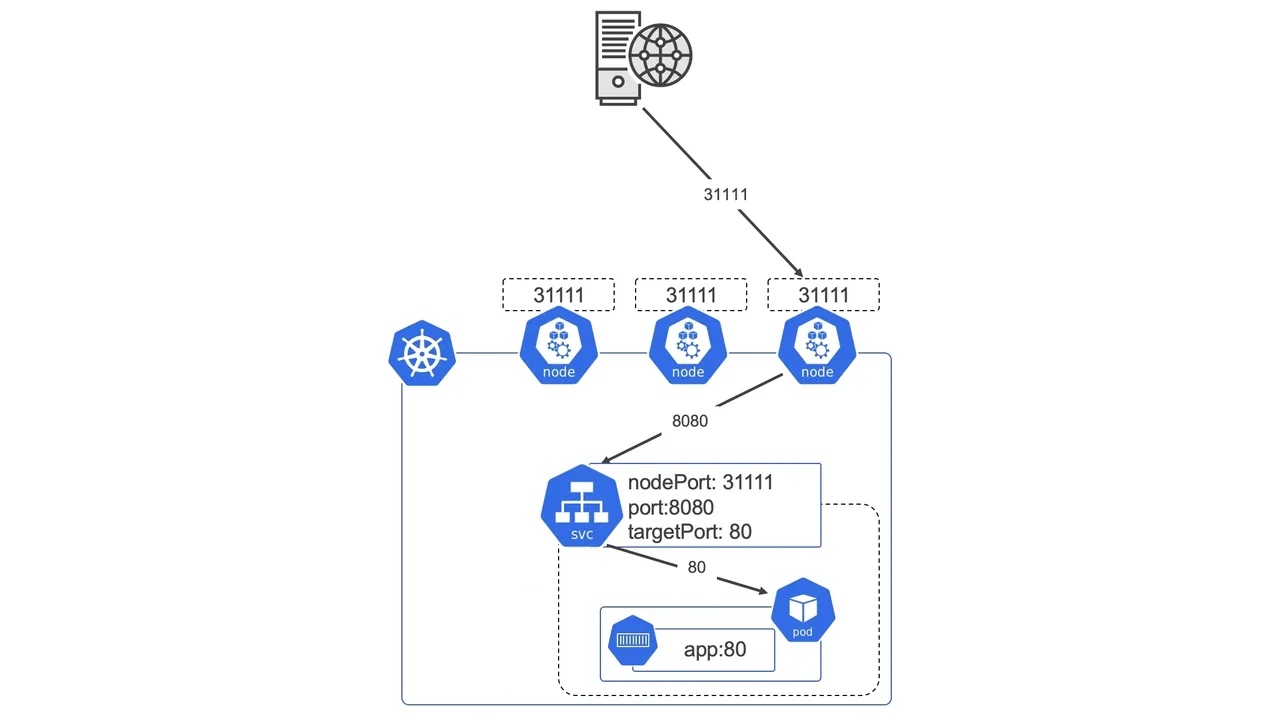
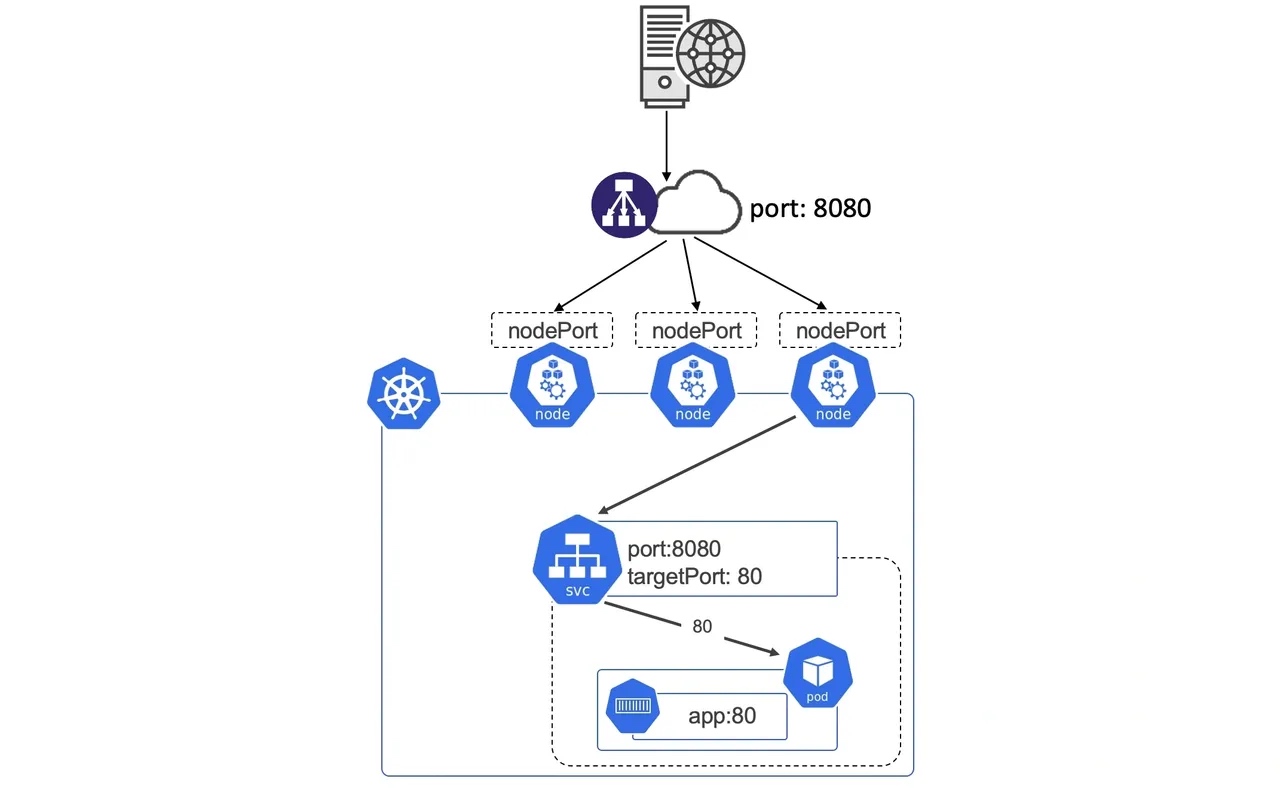
# kubectl get all
NAME READY STATUS RESTARTS AGE
pod/whoami-767d459f67-qffqw 1/1 Running 0 23m
pod/whoami-767d459f67-xdv9p 1/1 Running 0 23m
pod/whoami-767d459f67-gwpgx 1/1 Running 0 23m
NAME READY UP-TO-DATE AVAILABLE AGE
deployment.apps/whoami 3/3 3 3 23m
NAME DESIRED CURRENT READY AGE
replicaset.apps/whoami-767d459f67 3 3 3 23m
其次,安装busybox进行调试
安装一个包含有curl的busybox方便后续调试:
kubectl run busybox-curl --image=yauritux/busybox-curl --command -- sleep 3600